Delivering Privacy and Security using Protecto, LangChain, and OpenAI’s GPT
In the age of digital information, the development of chatbots and language models has revolutionized the way we interact with technology. One promising application of these innovations is the creation of document chatbots capable of extracting valuable insights from documents while safeguarding sensitive data. In this document, we will explore the critical role that Protecto plays in enhancing the privacy and security of such chatbots along with LangChain, and OpenAI’s GPT.
Why is this important?
Protecting user privacy and securing sensitive data is paramount in today’s digital landscape. Privacy-preserving chatbots, specifically designed to handle confidential information, are crucial for various industries, including healthcare, finance, and legal sectors. Here’s why Protecto stands out as the solution to these critical concerns:
- Data Security: In any industry, safeguarding sensitive information (PII) is imperative. Protecto Privacy Vault empowers chatbots including any Large Language Models (LLMs) to derive insights from confidential records and documents while maintaining strict privacy standards. Its absence could pose significant challenges to organizations in adhering to privacy regulations.
- Compliance: Many industries are subject to strict data protection regulations and compliance standards. Protecto ensures that chatbots or LLMs adhere to these regulations, mitigating the risk of costly legal consequences and reputational damage.
- Internal Data Leaks: Protecto Privacy Vault safeguards against internal data leaks by masking sensitive details in chats or documents for LLM processing. The risk emerges when unmasking this data for user access. Protecto’s controlled unmasking feature is key here, ensuring secure data re-exposure, thus preventing potential data breaches and maintaining data integrity.
- Enhanced User Trust: By using Protecto, chatbot developers can assure users that their data remains confidential and protected. This trust is essential for user adoption and satisfaction.
How It Works?
At its essence, a document chatbot operates much like OpenAI’s GPT. Just as with OpenAI’s GPT, where you can input text to request summaries or answers, the document chatbot involves extracting text from a singular document, such as a PDF. This extracted text undergoes a process of masking for enhanced protection and is subsequently fed into a finely tuned language model, akin to OpenAI’s GPT. This tuned model is specifically trained to recognize the tokenized text, empowering you to pose questions or seek information based on the content within the document.
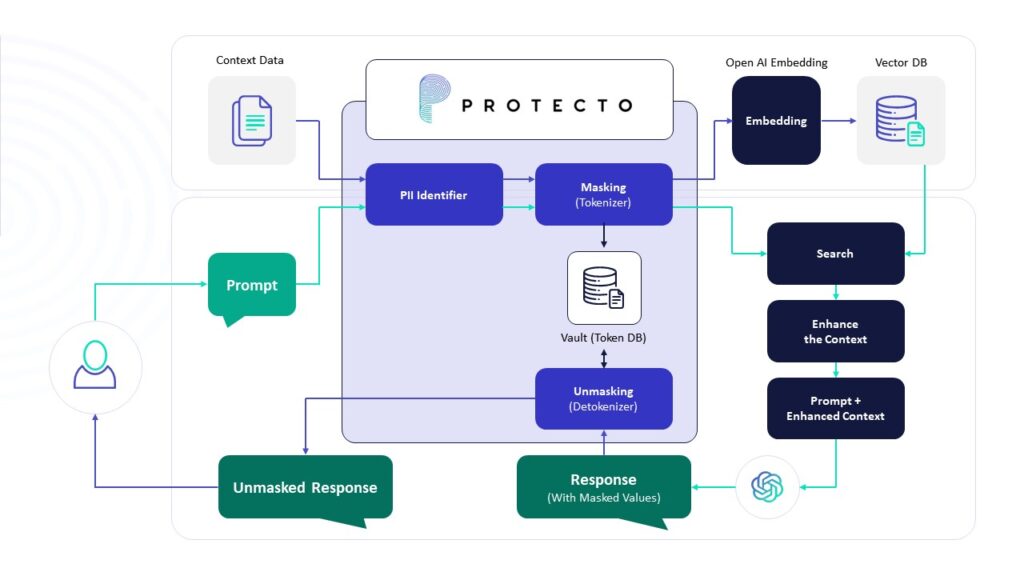
Embeddings and Vector Stores
We aim to efficiently distill pertinent information from our documents by leveraging embeddings and vector stores. Embeddings, serving as semantic representations, enable us to organize and categorize text fragments based on meaning. Breaking down our documents into smaller segments, we employ an embedding transformer to characterize each piece by its semantic essence.
An embedding provides a vector representation, assigning coordinates to text snippets. Proximity in these vectors indicates semantic similarity, facilitating the storage of embedding vectors in a vector store alongside corresponding text fragments.
With a prompt in hand, our embeddings transformer identifies the text segments most semantically relevant to it, employing the cosine similarity method. This method calculates the similarity between documents and a question, offering a robust means of associating prompts with related text snippets from the vector store.
This refined subset of information, now aligned with our prompt, serves as the context for querying the Language Model (LLM). By feeding only the relevant information into the prompt’s context, we optimize the efficiency of the interaction with the LLM, ensuring a more targeted and effective exchange.
Code:
- Let’s install all the packages we will need for our setup
- Initially, text extraction is performed using PDF Miner.
- The extracted text is organized into ‘n’ lines and subsequently processed through the Protecto’s Tokenization API, where sensitive data, such as personally identifiable information (PII), is masked.
- We use Protecto mask function to tokenize the PII data in the text
- The sentence undergoes processing through split_text_with_overlap, a function that accepts the text, chunk size, and overlap as parameters. This function divides the entire text into specific chunks, ensuring each chunk contains an overlap of words to maintain contextual coherence.
- We then create OpenAIEmbeddings to these chunks and Store the embeddings in a chroma DB.
ConversationBufferMemory usage is straightforward. It simply keeps the entire conversation in the buffer memory
ConversationalRetrievalChain is a kind of chain used to be provided with a query and to answer it using documents retrieved from the query. It is one of the many possibilities to perform Retrieval-Augmented Generation.
But it won’t only answer your last query, it will also use the chat history to improve the quality of the RAG by taking into account past queries and answers when retrieving documents, or feeding the LLM with those documents and asking it to answer a question.
Loop where the user is prompted to input a question. If the user enters ‘exit’ or presses Ctrl+C, the program terminates gracefully. Otherwise, the input question is processed through the conversational retrieval chain (bot), and the corresponding answer is printed. The loop continues until the user chooses to exit by entering ‘exit’ or using Ctrl+C.
In summary, Protecto serves as the cornerstone for privacy-preserving chatbots, ensuring the security of sensitive data, compliance with regulations, and the trust of users. Without Protecto, chatbots may encounter significant issues, including data exposure, legal repercussions, and a loss of trust. Incorporating Protecto into your chatbot development is a critical step toward creating a secure and trustworthy document chatbot.
import os
import traceback
import logging
import mimetypes
import nltk
from nltk.tokenize import sent_tokenize
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import Chroma
from langchain.memory import ConversationBufferMemory, ChatMessageHistory
from protecto_ai import ProtectoVault
from pdfminer.high_level import extract_text
from dotenv import load_dotenv
load_dotenv()
nltk.download('punkt')
class FileQuestioner:
def __init__(self):
self.chunk_size = int(os.getenv("CHUNK_SIZE"))
self.model_name = os.getenv('MODEL_NAME')
self.max_tokens = int(os.getenv('MAX_TOKENS'))
self.sentence_count_limit = int(os.getenv('SENTENCE_COUNT_LIMIT'))
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
protecto_api_key = os.getenv("PROTECTO_API_KEY")
file = os.getenv("FILE_PATH")
if not file:
raise ValueError("File path not specified")
mime_type, _ = mimetypes.guess_type(file)
if not mime_type == "application/pdf":
return
self.pdf_content = extract_text(file)
self.protecto_object = ProtectoVault(protecto_api_key)
self.concat_sentence = ''
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
filename="Error.log", filemode='w')
self.logger = logging.getLogger()
def sentence_tokenize(self, texts):
try:
sentence_count = 0
sentence_appended = ""
sentences = sent_tokenize(texts)
for each_line in sentences:
sentence_appended += each_line + " "
sentence_count += 1
if sentence_count >= self.sentence_count_limit:
self.logger.info("Masking Started")
self.logger.info(f"{sentence_appended}")
masked_sentence = self.mask(sentence_appended)
self.logger.info("Masking Completed")
self.concat_sentence += masked_sentence
sentence_appended = ""
sentence_count = 0
if sentence_appended:
masked_sentence = self.mask(sentence_appended)
self.concat_sentence += masked_sentence
self.logger.info("Sentences are MASKED, appended and sent to Process")
self.process(self.concat_sentence)
except Exception as e:
self.logger.error(f"Error in sentence tokenize: {e}\n\n Trace: {traceback.format_exc()}")
raise e
def mask(self, sentence_appended):
masking_sentence = self.protecto_object.mask({"mask": [{"value": sentence_appended}]})
masked_sentence = masking_sentence["data"][0]["token_value"]
return masked_sentence
def split_text_with_overlap(self, text, chunk_size, overlap_word_size):
try:
self.logger.info("Splitting text with overlap started")
# Custom tokenization to respect special tags
words = []
current_word = ""
inside_tag = False
for char in text:
if char == '<':
inside_tag = True
if current_word:
words.append(current_word)
current_word = ""
elif char == '>':
inside_tag = False
current_word += char
words.append(current_word)
current_word = ""
continue
current_word += char
if not inside_tag and char.isspace():
words.append(current_word)
current_word = ""
if current_word:
words.append(current_word)
# Splitting into chunks with overlap
chunks = []
current_chunk = []
current_length = 0
for word in words:
current_length += len(word)
if current_length >= chunk_size:
chunks.append(''.join(current_chunk).strip())
current_chunk = current_chunk[-overlap_word_size:]
current_length = len(''.join(current_chunk))
current_chunk.append(word)
if current_chunk:
chunks.append(''.join(current_chunk).strip())
self.logger.info("Splitting text with overlap completed")
return chunks
except Exception as e:
self.logger.error(f'Error in split text with overlap: {e}\n\n Trace: {traceback.format_exc()}')
raise e
def process(self, output_masked_sentences):
try:
overlap_word_size = 4
texts = self.split_text_with_overlap(text=output_masked_sentences, chunk_size=self.chunk_size,
overlap_word_size=overlap_word_size)
self.logger.info(
f"Text split with overlap and completed, with {self.chunk_size} as chunk size and {overlap_word_size} "
f"as overlap")
embeddings = OpenAIEmbeddings()
retriever = Chroma.from_texts(texts, embeddings,)
self.logger.info('Embedding Created')
message_history = ChatMessageHistory()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True, output_key='answer',
chat_memory=message_history)
llm = ChatOpenAI(model_name=self.model_name, max_tokens=self.max_tokens)
bot = ConversationalRetrievalChain.from_llm(
llm=llm, retriever=retriever.as_retriever(), return_source_documents=True,
memory=memory, chain_type="stuff")
while True:
try:
query = input("Enter the question (type 'exit' or Ctrl+c to end): ")
if query.lower() == "exit":
print("\nExiting.")
break
val = bot({"question": query})
print(val["answer"], "\n")
except KeyboardInterrupt:
print("\nExiting.")
break
except Exception as e:
self.logger.error(f"Error in Process :{e}\n\n Trace: {traceback.format_exc()}")
raise e
def execute(self):
try:
self.sentence_tokenize(self.pdf_content)
except Exception as e:
self.logger.error(f"Error in execute: {e}\n\n Trace {traceback.format_exc()}")
raise RuntimeError(f"Error: {e}")
obj = FileQuestioner()
obj.execute()
.env file
OPENAI_API_KEY="" FILE_PATH="" PROTECTO_API_KEY="" MODEL_NAME="" MAX_TOKENS="" CHUNK_SIZE="" SENTENCE_COUNT_LIMIT=""
OPENAI_API_KEY - OpenAI key FILE_PATH - Input file path PROTECTO_API_KEY - Protecto api key MODEL_NAME - Fine tuned OpenAI model name MAX_TOKENS(Integer Value) - Number of output tokens. CHUNK_SIZE(Integer Value) - embedding created for number of sentences. SENTENCE_COUNT_LIMIT (an Integer value) - number of sentences that tokenizes at a time.
Fine tuning steps:
- The training file can be downloaded here.
- Use the downloaded file to fine tune the model in OpenAI platform.
- Once the fine tune job is completed, copy the model name and paste in the env file under the key, ‘MODEL_NAME’.
If you prefer not to sign up and use Protecto APIs, you can replace the masking with your own APIs, following the same input and output structure of Protecto’s APIs. Refer to the full Protecto Tokenization Documentation here.



